 Websites are made of web pages. Every webpage is made of html tags. And every webpage has a unique address called URL which stands for Uniform Resource Locator. Using which we can request the webpage html code from the server. Once we send the request, the server will give us the html file for the webpage and our browser translates the code into readable English. This is the process that takes place every time we browse the internet.
Websites are made of web pages. Every webpage is made of html tags. And every webpage has a unique address called URL which stands for Uniform Resource Locator. Using which we can request the webpage html code from the server. Once we send the request, the server will give us the html file for the webpage and our browser translates the code into readable English. This is the process that takes place every time we browse the internet.In today’s post, we will see how to do that without the browser and rather through python. And also we will see how to grab all the links present on a website. A link is another URL. There can be many uses of doing this. For example, a web crawler does this all the time. It goes through the html code of a website and copies the links. And it visits those individual links and looks for other links in that page too. This is how the Google indexes pages. It crawls the whole of the internet every day.
Python is very easy, as is this process. So let’s get started with the program. For this program we will need two modules:
- Urllib2
- Beautifulsoup4
Urllib2 is used for sending GET requests to the server where the website resides. This will allow us to locally save the HTML code of the webpage on our own machine.
BeautifulSoup4 is used for finding specific elements present in the HTML code. It allows us to isolate any specific tag like 'a' or 'div' or any other tag. It also lets us play around with its contents.
Steps:
- First of all we are going to import both libraries into our program.
- Then we will get the HTML code of the desired webpage using urllib2.urlopen() function.
- Then we are going to parse the HTML code using BeautifulSoup() function.
- Once we have the beautifulsoup object ready, it is very easy to fetch all the links. All the links are written inside the anchor tag .
- To get all the anchor tags, we use the function find_all(‘a’) which comes with beautifulsoup. This will give us a list of all the anchor tags.
- But we don’t want the whole anchor tag. We only need the URLs. For that we can use the function get(‘href’) which also is a function of beautifulsoup. It will fetch all the URLs from their respective tags.
- We make a list of all such URLs on the page and we are done.
This will only crawl the page specified. If you want to crawl the whole website, the process should be repeated for each link in the list you have made. That will take a lot of time.
Also not all the links in the anchor tags will be complete links. Some of them will not have the domain name mentioned in them. For example, instead of http://profsmythe.blogspot.com /2015/12/checking-for-email-address-validity.html">http://profsmythe.blogspot.com/2015/12/checking-for-email-address-validity.html, only http://profsmythe.blogspot.com /2015/12/checking-for-email-address-validity.html">/2015/12/checking-for-email-address-validity.html will be given. So to access them we will have to prefix them with the domain name of the website starting with http://.
All theses links can be copied to a file for future use of can be used directly used in this program itself.
This is the code for the program:

This is what the output would look like:
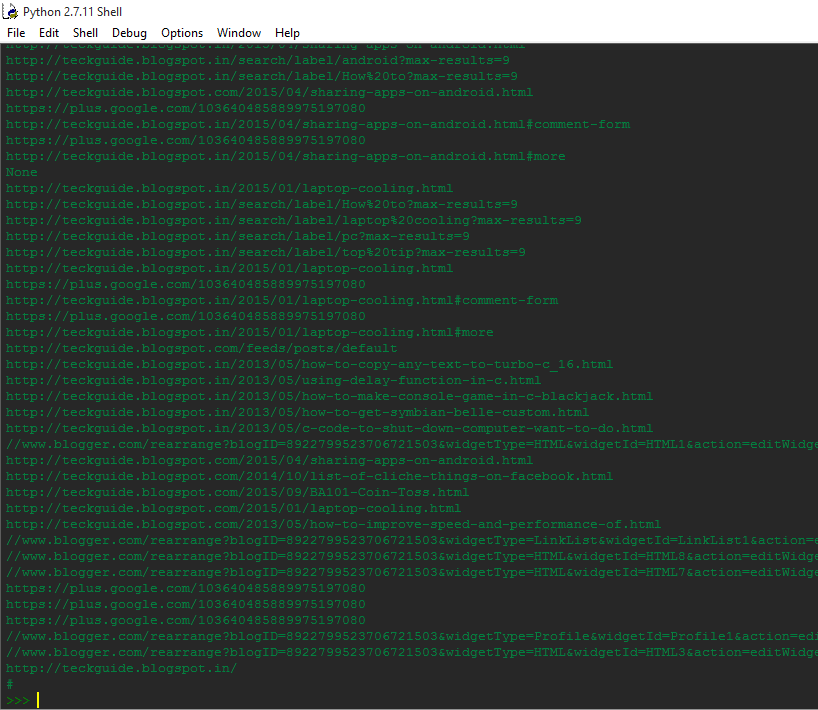
Pretty easy isn’t it?
That’s all for today. If you have any questions, please ask in the comments below or make use of the ‘contacts us’ button.
Don’t forget to subscribe to the newsletter to receive future such posts right to your inbox.
Thank you.






0 comments:
Post a Comment